#Individual level analysis
#Remove
rm(list = ls())
getwd()
# 1. Load packages --------------------------------------------------------
pacman::p_load(lme4,reghelper,haven,stargazer,ggplot2,dplyr, patchwork,
texreg,ggeffects,sjmisc,statar,summarytools,psych,sjPlot,
plm,lmtest,foreign)
# 2. Load data N = 25,286 ------------------------------------------------------
Latinobarometro18_20_LARR<- readRDS(file = "input/Latinobarometro18_20_LARR.rds")
Latinobarometro18_20_LARR <- as.data.frame(Latinobarometro18_20_LARR) #para evitar error en figuras
#3 Logistic regressions: trust in unions -----
log1<- glm(trustunions_life_dummy ~ class3+female+edad+pais+ano+
trust_pol_institutions+pol_pos,
data = Latinobarometro18_20_LARR,
family = "binomial")
log2<- glm(trustunions_life_dummy ~ class3+female+edad+pais+ano+
trust_pol_institutions+pol_pos+class3*ano,
data = Latinobarometro18_20_LARR,
family = "binomial") #clase*year = Sign
log3<- glm(trustunions_life_dummy ~ class3+female+edad+pais+ano+
trust_pol_institutions+pol_pos+pol_pos*ano,
data = Latinobarometro18_20_LARR,
family = "binomial") #pol pos*year = Sign
log4<- glm(trustunions_life_dummy ~ class3+female+edad+pais+ano+
trust_pol_institutions+pol_pos+trust_pol_institutions*ano,
data = Latinobarometro18_20_LARR,
family = "binomial") #trust*year = NS
log5<- glm(trustunions_life_dummy ~ class3+female+edad+pais+ano+
trust_pol_institutions+pol_pos+pais*ano,
data = Latinobarometro18_20_LARR,
family = "binomial") #country*year = Sign
m1_R2<-DescTools::PseudoR2(log1)
m2_R2<-DescTools::PseudoR2(log2)
m3_R2<-DescTools::PseudoR2(log3)
m4_R2<-DescTools::PseudoR2(log4)
m5_R2<-DescTools::PseudoR2(log5)
screenreg(list(log1,log2,log3,log4,log5),
custom.gof.rows=list("Pseudo R2" = c(m1_R2,m2_R2,m3_R2,m4_R2,m5_R2)),
digits = 3,stars = c(0.001, 0.01, 0.05, 0.1),symbol = "†")
##Word:
htmlreg(list(log1,log2,log3,log4,log5),
custom.gof.rows=list("Pseudo R2" = c(m1_R2,m2_R2,m3_R2,m4_R2,m5_R2)),
file = "LogisticRegModels.doc",
custom.model.names = c("Model 1",
"Model 2",
"Model 3",
"Model 4",
"Model 5"),
digits = 4,
stars = c(0.001, 0.01, 0.05, 0.1),symbol = "†")
#3.2. Análisis suplementarios
#Interaccón clase * posición política
log1.1<- glm(trustunions_life_dummy ~ class3+female+edad+pais+ano+
trust_pol_institutions+pol_pos+class3*pol_pos,
data = Latinobarometro18_20_LARR,
family = "binomial") #clase* pol pos = NS
#Interaccón clase * confianza
log1.2<- glm(trustunions_life_dummy ~ class3+female+edad+pais+ano+
trust_pol_institutions+pol_pos+class3*trust_pol_institutions,
data = Latinobarometro18_20_LARR,
family = "binomial") #clase* pol pos = NS
#Modelo con politizacion & disposicion a la accion colectiva (sólo 2020)
log6<- glm(trustunions_life_dummy ~ class3+female+edad+pais+
trust_pol_institutions+pol_pos+
politicization+collective_action,
data = Latinobarometro18_20_LARR,
family = "binomial")
m1.1_R2<-DescTools::PseudoR2(log1.1)
m1.2_R2<-DescTools::PseudoR2(log1.2)
m6_R2<-DescTools::PseudoR2(log6)
screenreg(list(log1.1,log1.2,log6),
custom.gof.rows=list("Pseudo R2" = c(m1.1_R2,m1.2_R2,m6_R2)),
digits = 3,stars = c(0.001, 0.01, 0.05, 0.1),symbol = "†")
# 5.Figures / predicted probabilities ---------------------------------------
#Efectos directos: Modelo 1----
#class effect (ordenadas de menor a mayor)
class_effect<-ggeffects::ggpredict(log1, terms = c("class3"))%>%
ggplot(aes(x = reorder(x, predicted), y=predicted))+
geom_bar(stat="identity",color="brown3", fill="brown3")+
geom_errorbar(aes(ymin = conf.low, ymax = conf.high), width=.1) +
labs(title="Clase social", x = "", y = "")+
theme_bw() +
theme(plot.title = element_text(size = 12),
axis.text.x = element_text(angle = 0, vjust = 0.5, size = 10),
axis.text.y = element_text(vjust = 0.5, size = 10))+
scale_x_discrete(labels=c("1. Gran empleador"="Empleadores",
"2. Pequeño empleador"="Pequeños\nempleadores",
"3. Pequeño burgués formal" = "Pequeña\nburguesía",
"4. Clase media"="Clase\nmedia",
"5. Obrero"="Clase\ntrabajadora",
"6. Autoempleado informal"="Autoempleados\ninformales"))+
scale_y_continuous(limits = c(0,0.45),breaks=seq(0,0.45, by = 0.05),
labels = scales::percent_format(accuracy = 1L))
#Probabilities pol position (ordenadas de menor a mayor)
polposition_effect<-ggeffects::ggpredict(log1, terms = c("pol_pos"))%>%
ggplot(aes(x = reorder(x, predicted), y=predicted))+
geom_bar(stat="identity",color="deepskyblue4", fill="deepskyblue4")+
geom_errorbar(aes(ymin = conf.low, ymax = conf.high), width=.1) +
labs(title="", x = "", y = "")+
theme_bw() +
theme(plot.title = element_text(size = 12),
axis.text.x = element_text(angle = 0, vjust = 0.5, size = 10),
axis.text.y = element_text(vjust = 0.5, size = 10))+
scale_x_discrete(labels=c("Izquierda"="Izquierda",
"Centro"="Centro",
"Derecha" = "Derecha",
"Ninguno"="Ninguna"))+
scale_y_continuous(breaks=c(0.05,0.1,0.15,0.2,0.25,0.3,0.35), limits = c(0,0.35),
labels = scales::percent_format(accuracy = 1L))
#Trust in institutions
frq(Latinobarometro2020_LARR$trust_pol_institutions)
trustinst_effect<-ggeffects::ggpredict(log1, terms="trust_pol_institutions [all]")%>% #all muestra todos los valores de X
ggplot(mapping=aes(x = x, y=predicted))+
labs(title="b.Confianza en instituciones", x = "", y = "")+
theme_bw() +
geom_smooth(se=FALSE)+
geom_ribbon(aes(ymin = conf.low, ymax = conf.high), alpha = .2, fill = "black") +
theme(plot.title = element_text(size = 12),
axis.text.x = element_text(angle = 0, vjust = 0.5, size = 10),
axis.text.y = element_text(vjust = 0.5, size = 10))+
scale_x_continuous(breaks=seq(from = 0, to = 15, by = 1))+
scale_y_continuous(limits = c(0,0.9),breaks=seq(0,0.9, by = 0.1),
labels = scales::percent_format(accuracy = 1L))
#Country effect (ordenado de menor a mayor confianza)
country_effect_tab<-ggeffects::ggpredict(log1, terms = c("pais"))
country_effect<-ggeffects::ggpredict(log1, terms = c("pais"))%>%
ggplot(aes(x = reorder(x, predicted), y=predicted))+
geom_bar(stat="identity",color="grey", fill="grey")+
geom_errorbar(aes(ymin = conf.low, ymax = conf.high), width=.1) +
labs(title="", x = "", y = "")+
theme_bw() +
theme(plot.title = element_text(size = 12),
axis.text.x = element_text(angle = 0, vjust = 0.5, size = 10),
axis.text.y = element_text(vjust = 0.5, size = 10))+
scale_y_continuous(limits = c(0,0.5),breaks=seq(0,0.5, by = 0.05),
labels = scales::percent_format(accuracy = 1L))
#Efectos interacción: Modelos 2 - 5------
#Interaccion clase /año
Int_Clase_Ano<-ggpredict(log2,terms = c("class3","ano")) %>%
ggplot(aes(x = reorder(x, predicted), y=predicted,shape = group, color = group))+
geom_point(size = 2.5,position = position_dodge(.1))+
geom_line(aes(group=group),position = position_dodge(.1)) +
geom_errorbar(aes(ymin = conf.low, ymax = conf.high), width=.1,position = position_dodge(.1))+
labs(title="", x = "", y = "")+
scale_x_discrete(labels=c("1. Gran empleador"="Empleadores",
"2. Pequeño empleador"="Pequeños\nempleadores",
"3. Pequeño burgués formal" = "Pequeña\nburguesía",
"4. Clase media"="Clase\nmedia",
"5. Obrero"="Clase\ntrabajadora",
"6. Autoempleado informal"="Autoempleados\ninformales"))+
scale_shape_discrete(name = "Año",
limits = c("2018", "2020"),
labels = c("2018", "2020")) +
scale_color_manual(name = "Año",
limits = c("2018", "2020"),
labels = c("2018", "2020"),
values = c("gray60", "black")) +
scale_y_continuous(limits = c(0,0.45),breaks=seq(0,0.45, by = 0.05),
labels = scales::percent_format(accuracy = 1L)) +
theme_bw() +
labs(title="a) Clase*Año", y = "") +
theme(plot.title = element_text(size = 11),
axis.text=element_text(size=10))
#Interaccion pol position /año
Int_PolPos_Ano<-ggpredict(log3,terms = c("pol_pos","ano")) %>%
ggplot(aes(x = reorder(x, predicted), y=predicted,shape = group, color = group))+
geom_point(size = 2.5,position = position_dodge(.1))+
geom_line(aes(group=group),position = position_dodge(.1)) +
geom_errorbar(aes(ymin = conf.low, ymax = conf.high), width=.1,position = position_dodge(.1))+
labs(title="", x = "", y = "")+
scale_x_discrete(labels=c("Izquierda"="Izquierda",
"Centro"="Centro",
"Derecha" = "Derecha",
"Ninguno"="Ninguna"))+
scale_shape_discrete(name = "Año",
limits = c("2018", "2020"),
labels = c("2018", "2020")) +
scale_color_manual(name = "Año",
limits = c("2018", "2020"),
labels = c("2018", "2020"),
values = c("gray60", "black")) +
scale_y_continuous(limits = c(0,0.35),breaks=seq(0,0.35, by = 0.05),
labels = scales::percent_format(accuracy = 1L)) +
theme_bw() +
labs(title="b) Posición política*Año", y = "") +
theme(plot.title = element_text(size = 11),
axis.text=element_text(size=10))
#Interaccion pais*año (ordenado de menor a mayor confianza)
Int_Pais_Ano<-ggpredict(log5,terms = c("pais","ano")) %>%
ggplot(aes(x = reorder(x, predicted), y=predicted,shape = group, color = group))+
geom_point(size = 2.5,position = position_dodge(.1))+
geom_line(aes(group=group),position = position_dodge(.1)) +
geom_errorbar(aes(ymin = conf.low, ymax = conf.high), width=.2,position = position_dodge(.1))+
scale_x_discrete(name = "")+
scale_shape_discrete(name = "Año",
limits = c("2018", "2020"),
labels = c("2018", "2020")) +
scale_color_manual(name = "Año",
limits = c("2018", "2020"),
labels = c("2018", "2020"),
values = c("gray60", "black")) +
scale_y_continuous(limits = c(0,0.5),breaks=seq(0,0.5, by = 0.05),
labels = scales::percent_format(accuracy = 1L)) +
theme_bw() +
labs(title="", y = "") +
theme(plot.title = element_text(size = 11),
axis.text=element_text(size=10))
#Paste & Save figures--------------------------------
##Patchwork: Figuras 1 - 4
#FIGURE 1: Patchwork (int clase*año + posicion pol*año)
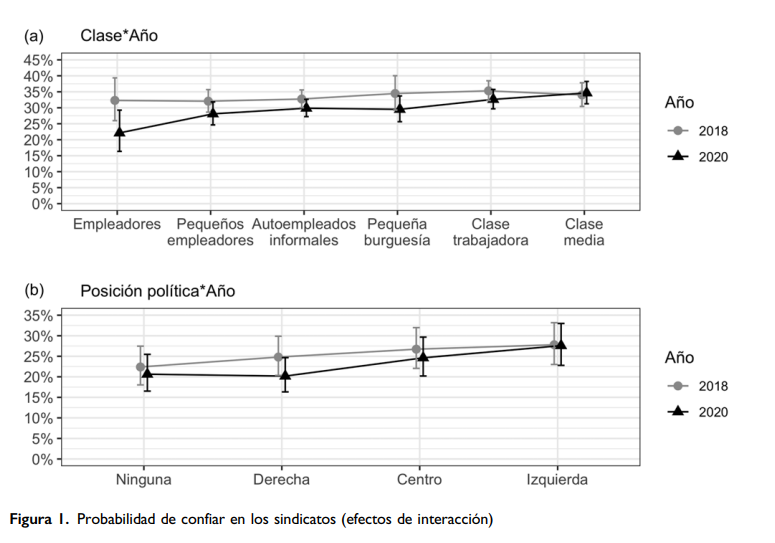
Figura1<- Int_Clase_Ano / Int_PolPos_Ano
#Save
ggsave(Figura1, filename = "Figura1.png",
device = "png",dpi = "retina", units = "cm",
width = 18,height = 12)
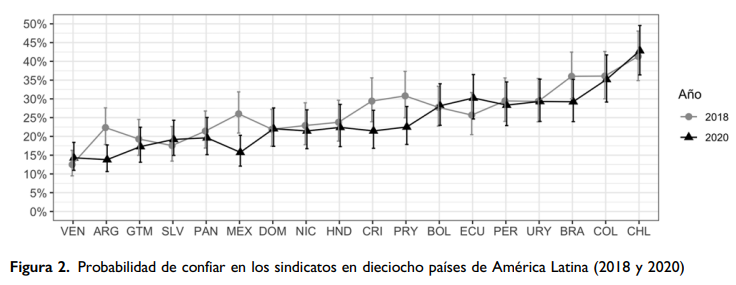
ggsave(Int_Pais_Ano, filename = "Figure2.png",
device = "png",dpi = "retina", units = "cm",
width = 22,height = 8)
Figura1
Int_Pais_Ano
#6. CONTEXTUAL LEVEL DATA (Modelo + otras variables)--------
#Modelo 1, sólo 2018 + predicted probabilities para país----
log1_2018<- glm(trustunions_life_dummy ~ class3+female+edad+pais+
trust_pol_institutions+pol_pos,
data = subset(Latinobarometro18_20_LARR, ano=="2018"),
family = "binomial")
screenreg(log1_2018,
digits = 3,stars = c(0.001, 0.01, 0.05, 0.1),symbol = "†")
#Predicted probabilities
pais2018_prob<-ggeffects::ggpredict(log1_2018, terms = c("pais"))
#Modelo 1, sólo 2020 + predicted probabilities para país----
log1_2020<- glm(trustunions_life_dummy ~ class3+female+edad+pais+
trust_pol_institutions+pol_pos,
data = subset(Latinobarometro18_20_LARR, ano=="2020"),
family = "binomial")
screenreg(log1_2020,
digits = 3,stars = c(0.001, 0.01, 0.05, 0.1),symbol = "†")
#Predicted probabilities
pais2020_prob<-ggeffects::ggpredict(log1_2020, terms = c("pais"))
#Trust in political institutions by country-
trustpolinst_country<-Latinobarometro2020_LARR %>%
group_by(pais) %>%
summarise(mean_trust = mean(trust_pol_institutions)) %>% print(n=nrow(.))
barchart_trustinst_country<-ggplot(trustinst_country,
aes(x = reorder(pais, mean_trust),
y = mean_trust)) +
geom_bar(stat = "identity") +
theme_bw() +
theme(axis.text.x = element_text(angle = 90, vjust = 0.6, size = 10),
axis.text.y = element_text(vjust = 0.5, size = 9)) +
scale_y_continuous(breaks=seq(from = 0, to = 15, by = 0.5))+
labs(title = "Confianza en instituciones por país", x = "", y = "")
#Unions - perceived power by country
frq(Latinobarometro18_20_LARR$unions_perceivedpower)
sjPlot::tab_xtab(var.row = Latinobarometro18_20_LARR$pais,
var.col = Latinobarometro18_20_LARR$unions_perceivedpower,
title = "perceived power of unions by country", show.row.prc = TRUE)
#7. Modelos suplementarios (politizacion & accion colectiva, 2020)----
#Politicization
frq(Latinobarometro2020_LARR$politicization)
politicization_effect<-ggeffects::ggpredict(log6, terms="politicization [all]")%>% #all muestra todos los valores de X
ggplot(mapping=aes(x = x, y=predicted))+
labs(title="Politicization", x = "", y = "")+
theme_bw() +
geom_smooth(se=FALSE)+
geom_ribbon(aes(ymin = conf.low, ymax = conf.high), alpha = .2, fill = "black") +
theme(plot.title = element_text(size = 12),
axis.text.x = element_text(angle = 0, vjust = 0.5, size = 10),
axis.text.y = element_text(vjust = 0.5, size = 10))+
scale_x_continuous(breaks=seq(from = 0, to = 12, by = 1))+
scale_y_continuous(breaks=c(0.1,0.2,0.3,0.4,0.5), limits = c(0,0.55))
#Collective action
frq(Latinobarometro2020_LARR$collective_action)
collectiveaction_effect<-ggeffects::ggpredict(log6, terms="collective_action [all]")%>% #all muestra todos los valores de X
ggplot(mapping=aes(x = x, y=predicted))+
labs(title="Collective action", x = "", y = "")+
theme_bw() +
geom_smooth(se=FALSE)+
geom_ribbon(aes(ymin = conf.low, ymax = conf.high), alpha = .2, fill = "black") +
theme(plot.title = element_text(size = 12),
axis.text.x = element_text(angle = 0, vjust = 0.5, size = 10),
axis.text.y = element_text(vjust = 0.5, size = 10))+
scale_x_continuous(breaks=seq(from = 0, to = 8, by = 1))+
scale_y_continuous(breaks=c(0.1,0.2,0.3,0.4,0.5), limits = c(0,0.55))
#8.2 Figuras(NO Confidence Interval para DEMOSAL)----
DEMOSAL_class<-ggeffects::ggpredict(LOG3, terms = c("class3"))%>%
ggplot(aes(x = reorder(x, predicted), y=predicted))+
geom_bar(stat="identity",color="brown3", fill="brown3")+
geom_text(aes(label = scales::percent(predicted, accuracy=0.1)), vjust = -0.3)+
labs(title="a. Posición de clase", x = "", y = "")+
theme_bw() +
theme(plot.title = element_text(size = 12),
axis.text.x = element_text(angle = 0, vjust = 0.5, size = 10),
axis.text.y = element_text(vjust = 0.5, size = 10))+
scale_x_discrete(labels=c("1. Gran empleador"="Empleadores",
"2. Pequeño empleador"="Pequeños\nempleadores",
"3. Pequeño burgués formal" = "Pequeña\nburguesía",
"4. Clase media"="Clase\nmedia",
"5. Obrero"="Clase\ntrabajadora",
"6. Autoempleado informal"="Autoempleados\ninformales"))+
scale_y_continuous(breaks=c(0.05,0.1,0.15,0.2,0.25,0.3,0.35,0.40,0.45,0.5), limits = c(0,0.5))
DEMOSAL_polposition<-ggeffects::ggpredict(LOG3, terms = c("pol_pos"))%>%
ggplot(aes(x = reorder(x, predicted), y=predicted))+
geom_bar(stat="identity",color="deepskyblue4", fill="deepskyblue4")+
geom_text(aes(label = scales::percent(predicted, accuracy=0.1)), vjust = -0.3)+
labs(title="Posición política", x = "", y = "")+
theme_bw() +
theme(plot.title = element_text(size = 12),
axis.text.x = element_text(angle = 0, vjust = 0.5, size = 10),
axis.text.y = element_text(vjust = 0.5, size = 10))+
scale_x_discrete(labels=c("Izquierda"="Izquierda",
"Centro"="Centro",
"Derecha" = "Derecha",
"Ninguno"="Ninguna"))+
scale_y_continuous(breaks=c(0.05,0.1,0.15,0.2,0.25,0.3,0.35), limits = c(0,0.35))
DEMOSAL_politicization<-ggeffects::ggpredict(LOG3, terms="politicization [all]")%>% #all muestra todos los valores de X
ggplot(mapping=aes(x = x, y=predicted))+
labs(title="Politicization", x = "", y = "")+
theme_bw() +
geom_smooth(se=FALSE)+
geom_ribbon(aes(ymin = conf.low, ymax = conf.high), alpha = .2, fill = "black") +
theme(plot.title = element_text(size = 12),
axis.text.x = element_text(angle = 0, vjust = 0.5, size = 10),
axis.text.y = element_text(vjust = 0.5, size = 10))+
scale_x_continuous(breaks=seq(from = 0, to = 12, by = 1))+
scale_y_continuous(breaks=c(0.1,0.2,0.3,0.4,0.5), limits = c(0,0.55))
DEMOSALcountry<-ggeffects::ggpredict(LOG3, terms = c("pais"))%>%
ggplot(aes(x = reorder(x, predicted), y=predicted))+
geom_bar(stat="identity",color="brown2", fill="brown2")+
geom_text(aes(label = scales::percent(predicted, accuracy=0.1)), vjust = -0.3)+
labs(title="", x = "", y = "")+
theme_bw() +
theme(plot.title = element_text(size = 12),
axis.text.x = element_text(angle = 0, vjust = 0.5, size = 10),
axis.text.y = element_text(vjust = 0.5, size = 10))+
scale_y_continuous(breaks=c(0.05,0.1,0.15,0.2,0.25,0.3,0.35,0.40), limits = c(0,0.4))
#8. Descriptives---------
#Ind level variables
frq(Latinobarometro18_20_LARR$trustunions_life_dummy)
frq(Latinobarometro18_20_LARR$class3)
frq(Latinobarometro18_20_LARR$female)
frq(Latinobarometro18_20_LARR$edad)
frq(Latinobarometro18_20_LARR$trust_pol_institutions)
frq(Latinobarometro18_20_LARR$pol_pos)
frq(Latinobarometro18_20_LARR$trustunions_life_dummy)
frq(Latinobarometro18_20_LARR$class3)
frq(Latinobarometro18_20_LARR$female)
frq(Latinobarometro18_20_LARR$pol_pos)
Latinobarometro18_20_LARR %>%
select(edad,trust_pol_institutions) %>%
sum_up(d = FALSE, wt = NULL)
#Contextual analysis - correlaciones bivariadas
#Remove
rm(list = ls())
getwd()
# 1. Load packages --------------------------------------------------------
pacman::p_load(lme4,reghelper,haven,stargazer,ggplot2,dplyr,patchwork,
texreg,ggeffects,sjmisc,statar,summarytools,psych,sjPlot,
plm,lmtest,foreign,readxl)
# 2. Load data N = 18 ------------------------------------------------------
#Datos 2018 -------
ConfSindicatosAL2018<- read_xlsx("Data/Variables_contextuales2018_LARR.xlsx",
sheet = "Base_final",
range = NULL,
col_names = TRUE,
col_types = NULL,
na = "")
# Datos sin Argentina
ConfSindicatosAL_NoArg2018<-filter(ConfSindicatosAL2018,Pais != "ARG")
# Datos sin Venezuela
ConfSindicatosAL_NoVzla2018<-filter(ConfSindicatosAL2018,Pais != "VEN")
# Datos sin Argentina ni Venezuela
ConfSindicatosAL_NoArgVzla2018<-filter(ConfSindicatosAL2018,Pais != "ARG" & Pais != "VEN")
#Datos 2020 -------
ConfSindicatosAL<- read_xlsx("Data/Variables_contextuales2020_LARR.xlsx",
sheet = "Base_final",
range = NULL,
col_names = TRUE,
col_types = NULL,
na = "")
# Datos sin Argentina
ConfSindicatosAL_NoArg<-filter(ConfSindicatosAL,Pais != "ARG")
# Datos sin Venezuela
ConfSindicatosAL_NoVzla<-filter(ConfSindicatosAL,Pais != "VEN")
# Datos sin Argentina ni Venezuela
ConfSindicatosAL_NoArgVzla<-filter(ConfSindicatosAL,Pais != "ARG" & Pais != "VEN")
view_df(ConfSindicatosAL)
# 2.1. Descriptivos (2020)-----------
#Estadísticos descriptivos. N = 18
ConfSindicatosAL %>%
select(Confianza_sindicatos,Informalidad,Poder_percibido,
gobizq_2000_20,
Desocupacion2020,IPC,IPC_log,
Manif_Dif_2000_2010) %>%
sum_up(d = FALSE, wt = NULL)
#Estadísticos descriptivos. N = 17 (No Arg)
ConfSindicatosAL_NoArg %>%
select(Confianza_sindicatos,Informalidad,Poder_percibido_100,
gobizq_2000_20,
Desocupacion2020,IPC,IPC_log,
Manif_Dif_2000_2010) %>%
sum_up(d = FALSE, wt = NULL)
#Estadísticos descriptivos. N = 17 (No Ven)
ConfSindicatosAL_NoVzla %>%
select(Confianza_sindicatos,Informalidad,Poder_percibido_100,
gobizq_2000_20,
Desocupacion2020,IPC,IPC_log,
Manif_Dif_2000_2010) %>%
sum_up(d = FALSE, wt = NULL)
# 3. Correlation matrix------
# Datos 2018-----
#N = 18
ConfSindicatosAL2018 %>%
select(Confianza_sindicatos,Informalidad,
gobizq_2000_18,
Desocupacion2018,IPC,IPC_log,
Manif_Dif_15_08_Porc) %>%
corr.test(., alpha = 0.05,
method='pearson')
#N = 17 (sin Venezuela): Corr Inflación = -0,30
ConfSindicatosAL_NoVzla2018 %>%
select(Confianza_sindicatos,
IPC,IPC_log) %>%
corr.test(., alpha = 0.05,
method='pearson')
#N = 16 (sin Argentina ni Venezuela): Corr Inflación = -0,1
ConfSindicatosAL_NoArgVzla2018 %>%
select(Confianza_sindicatos,
IPC,IPC_log) %>%
corr.test(., alpha = 0.05,
method='pearson')
# 2020-----
#N = 18
ConfSindicatosAL %>%
select(Confianza_sindicatos,Informalidad,Poder_percibido_100,
gobizq_2000_20,
Desocupacion2020,IPC,IPC_log,
Manif_Dif_2000_2010) %>%
corr.test(., alpha = 0.05,
method='pearson')
#N = 17 (sin Argentina): Corr poder percibido = -0,11
ConfSindicatosAL_NoArg %>%
select(Confianza_sindicatos,
Poder_percibido_100) %>%
corr.test(., alpha = 0.05,
method='pearson')
#N = 17 (sin Venezuela): Corr Inflación = -0,33
ConfSindicatosAL_NoVzla %>%
select(Confianza_sindicatos,
IPC,IPC_log) %>%
corr.test(., alpha = 0.05,
method='pearson')
#N = 16 (sin Argentina ni Venezuela): Corr Inflación = -0,33
ConfSindicatosAL_NoArgVzla %>%
select(Confianza_sindicatos,
IPC,IPC_log) %>%
corr.test(., alpha = 0.05,
method='pearson')
# 4.2 Gráficos correlaciones 2018----
# a) Informalidad
Fig1_Informalidad2018<-ggplot(ConfSindicatosAL2018, aes(x=Informalidad,
y=Confianza_sindicatos,
label=Pais)) +
geom_point()+
geom_smooth(method=lm, se=FALSE)+
geom_text(hjust=0, vjust=-1, size=3)+
annotate(geom="text", x=75, y=0.025, label="r de Pearson = -0,34",fontface="bold")+
theme_bw()+
labs(title="a) Informalidad laboral (2018)",
x = "Tasa de informalidad", y = "Prob. de confiar en sindicatos")+
theme(plot.title = element_text(size = 12),
axis.text.x = element_text(angle = 0, vjust = 0.5, size = 10),
axis.text.y = element_text(vjust = 0.5, size = 10))+
scale_x_continuous(breaks=seq(from = 0, to = 90, by = 10))+
scale_y_continuous(breaks=c(0.1,0.2,0.3,0.4,0.5), limits = c(0,0.5))
# b) Desocupacion
Fig2_Desocup2018<-ggplot(ConfSindicatosAL2018, aes(x=Desocupacion2018,
y=Confianza_sindicatos,
label=Pais)) +
geom_point()+
geom_smooth(method=lm, se=FALSE)+
geom_text(hjust=0, vjust=-1, size=3)+
annotate(geom="text", x=11, y=0.025, label="r de Pearson = 0,32",fontface="bold")+
theme_bw()+
labs(title="b) Desocupación (2018)",
x = "Tasa de desocupación", y = " ")+
theme(plot.title = element_text(size = 12),
axis.text.x = element_text(angle = 0, vjust = 0.5, size = 10),
axis.text.y = element_text(vjust = 0.5, size = 10))+
scale_x_continuous(breaks=seq(from = 0, to = 13, by = 1))+
scale_y_continuous(breaks=c(0.1,0.2,0.3,0.4,0.5), limits = c(0,0.5))
# c) Inflación (IPC log)
Fig3_Inflacion2018<-ggplot(ConfSindicatosAL2018, aes(x=IPC_log,
y=Confianza_sindicatos,
label=Pais)) +
geom_point()+
geom_smooth(method=lm, se=FALSE)+
geom_text(hjust=0, vjust=-1, size=3)+
annotate(geom="text", x=8.5, y=0.025, label="r de Pearson = -0,40",fontface="bold")+
theme_bw()+
labs(title="c) Inflación (2018)",
x = "Índice anual de precios al consumidor (log)", y = "Prob. de confiar en sindicatos")+
theme(plot.title = element_text(size = 12),
axis.text.x = element_text(angle = 0, vjust = 0.5, size = 10),
axis.text.y = element_text(vjust = 0.5, size = 10))+
scale_x_continuous(breaks=seq(from = -1, to = 12, by = 1))+
scale_y_continuous(breaks=c(0.1,0.2,0.3,0.4,0.5), limits = c(0,0.5))
# d) Inflación (IPC log): Sin Argentina ni Venezuela
Fig4_Inflacion_NoArgVzla2018<-ggplot(ConfSindicatosAL_NoArgVzla2018, aes(x=IPC_log,
y=Confianza_sindicatos,
label=Pais)) +
geom_point()+
geom_smooth(method=lm, se=FALSE)+
geom_text(hjust=0, vjust=-1, size=3)+
annotate(geom="text", x=1.5, y=0.025, label="r de Pearson = -0,10",fontface="bold")+
theme_bw()+
labs(title="d) Inflación 2018 (sin Argentina ni Venezuela)",
x = "Índice anual de precios al consumidor (log)", y = " ")+
theme(plot.title = element_text(size = 12),
axis.text.x = element_text(angle = 0, vjust = 0.5, size = 10),
axis.text.y = element_text(vjust = 0.5, size = 10))+
scale_x_continuous(breaks=seq(from = -1.5, to = 2.5, by = 0.5))+
scale_y_continuous(breaks=c(0.1,0.2,0.3,0.4,0.5), limits = c(0,0.5))
# e) Poder de partidos de izquierda
Fig5_PoderIzq2018<-ggplot(ConfSindicatosAL2018, aes(x=gobizq_2000_18,
y=Confianza_sindicatos,
label=Pais)) +
geom_point()+
geom_smooth(method=lm, se=FALSE)+
geom_text(hjust=0, vjust=-1, size=3)+
annotate(geom="text", x=15, y=0.025, label="r de Pearson = 0,29",fontface="bold")+
theme_bw()+
labs(title="e) Años de gobiernos de izquierda (2000 - 2018)",
x = "Años de gobiernos de izquierda", y = "Prob. de confiar en sindicatos")+
theme(plot.title = element_text(size = 12),
axis.text.x = element_text(angle = 0, vjust = 0.5, size = 10),
axis.text.y = element_text(vjust = 0.5, size = 10))+
scale_x_continuous(breaks=seq(from = 0, to = 20, by = 1))+
scale_y_continuous(breaks=c(0.1,0.2,0.3,0.4,0.5), limits = c(0,0.5))
# f) Movilización social
Fig6_Movilizacion2018<-ggplot(ConfSindicatosAL2018, aes(x=Manif_Dif_15_08_Porc,
y=Confianza_sindicatos,
label=Pais)) +
geom_point()+
geom_smooth(method=lm, se=FALSE)+
geom_text(hjust=0, vjust=-1, size=3)+
annotate(geom="text", x=16, y=0.025, label="r de Pearson = 0,69",fontface="bold")+
theme_bw()+
labs(title="f) Cambio en la disposición a la acción colectiva (2008 - 2015)",
x = "Disposición a marchar y protestar", y = "")+
theme(plot.title = element_text(size = 12),
axis.text.x = element_text(angle = 0, vjust = 0.5, size = 10),
axis.text.y = element_text(vjust = 0.5, size = 10))+
scale_x_continuous(breaks=seq(from = -16, to = 22, by = 2))+
scale_y_continuous(breaks=c(0.1,0.2,0.3,0.4,0.5), limits = c(0,0.5))
# Patchwork 2018: Figuras 1 - 6 ------
#FIGURE 3.1 (todas las figuras juntas)
Figura3.1<- (Fig1_Informalidad2018 | Fig2_Desocup2018)
Figura3.2<- (Fig3_Inflacion2018 | Fig4_Inflacion_NoArgVzla2018)
Figura3.3<- (Fig5_PoderIzq2018 | Fig6_Movilizacion2018)
#Save
ggsave(Figura3.1, filename = "Figura3.1.png",
device = "png",dpi = "retina", units = "cm",
width = 32,height = 12)
#Save
ggsave(Figura3.2, filename = "Figura3.2.png",
device = "png",dpi = "retina", units = "cm",
width = 32,height = 12)
#Save
ggsave(Figura3.3, filename = "Figura3.3.png",
device = "png",dpi = "retina", units = "cm",
width = 32,height = 12)
# 4.2 Gráficos correlaciones 2020----
# 4.1. Informalidad
Fig1_Informalidad<-ggplot(ConfSindicatosAL, aes(x=Informalidad,
y=Confianza_sindicatos,
label=Pais)) +
geom_point()+
geom_smooth(method=lm, se=FALSE)+
geom_text(hjust=0, vjust=-1, size=3)+
annotate(geom="text", x=75, y=0.025, label="r de Pearson = -0,34",fontface="bold")+
theme_bw()+
labs(title="a) Informalidad laboral ",
x = "Tasa de informalidad", y = "Prob. de confiar en sindicatos")+
theme(plot.title = element_text(size = 12),
axis.text.x = element_text(angle = 0, vjust = 0.5, size = 10),
axis.text.y = element_text(vjust = 0.5, size = 10))+
scale_x_continuous(breaks=seq(from = 0, to = 90, by = 10))+
scale_y_continuous(breaks=c(0.1,0.2,0.3,0.4,0.5), limits = c(0,0.5))
# 4.2 Poder atribuido a los sindicatos
Fig2_PoderAtribuido<-ggplot(ConfSindicatosAL, aes(x=Poder_percibido_100,
y=Confianza_sindicatos,
label=Pais)) +
geom_point()+
geom_smooth(method=lm, se=FALSE)+
geom_text(hjust=0, vjust=-1, size=3)+
annotate(geom="text", x=45, y=0.025, label="r de Pearson = -0,34",fontface="bold")+
theme_bw()+
labs(title="b) Poder atribuido a los sindicatos",
x = "Poder atribuido", y = " ")+
theme(plot.title = element_text(size = 12),
axis.text.x = element_text(angle = 0, vjust = 0.5, size = 10),
axis.text.y = element_text(vjust = 0.5, size = 10))+
scale_x_continuous(breaks=seq(from = 0, to = 55, by = 5))+
scale_y_continuous(breaks=c(0.1,0.2,0.3,0.4,0.5), limits = c(0,0.5))
# 4.3 Poder atribuido a los sindicatos: sin Argentina
Fig3_PoderAtribuido_NoArg<-ggplot(ConfSindicatosAL_NoArg, aes(x=Poder_percibido_100,
y=Confianza_sindicatos,
label=Pais)) +
geom_point()+
geom_smooth(method=lm, se=FALSE)+
geom_text(hjust=0, vjust=-1, size=3)+
annotate(geom="text", x=21, y=0.025, label="r de Pearson = -0,11",fontface="bold")+
theme_bw()+
labs(title="c) Poder atribuido a los sindicatos (sin Argentina)",
x = "Poder atribuido", y = "Prob. de confiar en sindicatos")+
theme(plot.title = element_text(size = 12),
axis.text.x = element_text(angle = 0, vjust = 0.5, size = 10),
axis.text.y = element_text(vjust = 0.5, size = 10))+
scale_x_continuous(breaks=seq(from = 0, to = 26, by = 2))+
scale_y_continuous(breaks=c(0.1,0.2,0.3,0.4,0.5), limits = c(0,0.5))
# 4.4 Poder de partidos de izquierda
Fig4_PoderIzq<-ggplot(ConfSindicatosAL, aes(x=gobizq_2000_20,
y=Confianza_sindicatos,
label=Pais)) +
geom_point()+
geom_smooth(method=lm, se=FALSE)+
geom_text(hjust=0, vjust=-1, size=3)+
annotate(geom="text", x=15, y=0.025, label="r de Pearson = 0,25",fontface="bold")+
theme_bw()+
labs(title="d) Años de gobiernos de izquierda (2000 - 2020)", x = "Años de gobiernos de izquierda", y = " ")+
theme(plot.title = element_text(size = 12),
axis.text.x = element_text(angle = 0, vjust = 0.5, size = 10),
axis.text.y = element_text(vjust = 0.5, size = 10))+
scale_x_continuous(breaks=seq(from = 0, to = 20, by = 1))+
scale_y_continuous(breaks=c(0.1,0.2,0.3,0.4,0.5), limits = c(0,0.5))
# 4.5 Desocupacion
Fig5_Desocup<-ggplot(ConfSindicatosAL, aes(x=Desocupacion2020,
y=Confianza_sindicatos,
label=Pais)) +
geom_point()+
geom_smooth(method=lm, se=FALSE)+
geom_text(hjust=0, vjust=-1, size=3)+
annotate(geom="text", x=16, y=0.025, label="r de Pearson = 0,27",fontface="bold")+
theme_bw()+
labs(title="d) Desocupación",
x = "Tasa de desocupación", y = "Prob. de confiar en sindicatos")+
theme(plot.title = element_text(size = 12),
axis.text.x = element_text(angle = 0, vjust = 0.5, size = 10),
axis.text.y = element_text(vjust = 0.5, size = 10))+
scale_x_continuous(breaks=seq(from = 0, to = 19, by = 1))+
scale_y_continuous(breaks=c(0.1,0.2,0.3,0.4,0.5), limits = c(0,0.5))
#4.6 Inflación (IPC log)
Fig6_Inflacion<-ggplot(ConfSindicatosAL, aes(x=IPC_log,
y=Confianza_sindicatos,
label=Pais)) +
geom_point()+
geom_smooth(method=lm, se=FALSE)+
geom_text(hjust=0, vjust=-1, size=3)+
annotate(geom="text", x=12, y=0.025, label="r de Pearson = -0,34",fontface="bold")+
theme_bw()+
labs(title="e) Inflación", x = "Índice anual de precios al consumidor (log)", y = " ")+
theme(plot.title = element_text(size = 12),
axis.text.x = element_text(angle = 0, vjust = 0.5, size = 10),
axis.text.y = element_text(vjust = 0.5, size = 10))+
scale_x_continuous(breaks=seq(from = 4, to = 14, by = 1))+
scale_y_continuous(breaks=c(0.1,0.2,0.3,0.4,0.5), limits = c(0,0.5))
#4.7 Inflación (IPC log): Sin Argentina ni Venezuela
Fig7_Inflacion_NoArgVzla<-ggplot(ConfSindicatosAL_NoArgVzla, aes(x=IPC_log,
y=Confianza_sindicatos,
label=Pais)) +
geom_point()+
geom_smooth(method=lm, se=FALSE)+
geom_text(hjust=0, vjust=-1, size=3)+
annotate(geom="text", x=4.75, y=0.025, label="r de Pearson = 0,15",fontface="bold")+
theme_bw()+
labs(title="f) Inflación (sin Argentina ni Venezuela)",
x = "Índice anual de precios al consumidor (log)", y = "Prob. de confiar en sindicatos")+
theme(plot.title = element_text(size = 12),
axis.text.x = element_text(angle = 0, vjust = 0.5, size = 10),
axis.text.y = element_text(vjust = 0.5, size = 10))+
scale_x_continuous(breaks=seq(from = 4.2, to = 4.8, by = 0.02))+
scale_y_continuous(breaks=c(0.1,0.2,0.3,0.4,0.5), limits = c(0,0.5))
# 4.8. Movilización social
Fig8_Movilizacion<-ggplot(ConfSindicatosAL, aes(x=Manif_Dif_2000_2010,
y=Confianza_sindicatos,
label=Pais)) +
geom_point()+
geom_smooth(method=lm, se=FALSE)+
geom_text(hjust=0, vjust=-1, size=3)+
annotate(geom="text", x=0.40, y=0.025, label="r de Pearson = 0,58",fontface="bold")+
theme_bw()+
labs(title="g) Cambio en la disposición a la acción colectiva (décadas 2000 - 2010)",
x = "Disposición a la acción colectiva", y = "")+
theme(plot.title = element_text(size = 12),
axis.text.x = element_text(angle = 0, vjust = 0.5, size = 10),
axis.text.y = element_text(vjust = 0.5, size = 10))+
scale_x_continuous(breaks=seq(from = -0.35, to = 0.55, by = 0.1))+
scale_y_continuous(breaks=c(0.1,0.2,0.3,0.4,0.5), limits = c(0,0.5))
# Patcwork 2020: Figuras 1 - 4 ------
#FIGURE 3.1 (todas las figuras juntas)
Figura3.1<- (Fig1_Informalidad | Fig2_PoderAtribuido) / (Fig3_PoderAtribuido_NoArg | Fig4_PoderIzq)
Figura3.2<- (Fig5_Desocup | Fig6_Inflacion) / (Fig7_Inflacion_NoArgVzla | Fig8_Movilizacion)
#Save
ggsave(Figura3.1, filename = "Figura3.1.png",
device = "png",dpi = "retina", units = "cm",
width = 32,height = 15)
#Save
ggsave(Figura3.2, filename = "Figura3.2.png",
device = "png",dpi = "retina", units = "cm",
width = 32,height = 15)